
金曜ごはん#36 「ジャンクな夜」
相変わらず(ry
なのですが、会社でも家でもやり続けていていろいろストレスになったので、家では他のことをやろうと思って、前々から欲しかったRSSリーダを作ってみました。
いまさらわざわざ作るのですから、当然ながら「人工知能搭載」です。
最初に書いたようにHieronymusばかりやっていて、それ自体は嫌ではないんですが、休日もなくずっとそれをやってるのってどうよ? とか思って先週の日曜日の夕方くらいに始めたものです。
また、以前は「情報収集」としてTwitterとか見たりしていたのですが、最近はあまり楽しくない場となってしまい、その「なんだかなぁ」という感じもあってちょっと敬遠気味です。 「近頃おごちゃん見ないな」と思った人がいたら、それは正解です。 最近アクティビティを低下させています。
まぁ「最新AI情報」みたいなのはやっぱりTwitterで見るしかなくて、そういったリストを作って読んでいるわけですけどね。 とは言え、やっぱりノイズは気になります。 うっかり見てしまったタイムラインで時間と精神をムダ使いしてしまうこともしばしばあります。
同じようなことは「ニュース」にもありまして、比較的最近までアレクサがニュースを伝えてくれるように設定していたのですが、ここのところ聞きたくもない、不愉快なニュースが多くなってしまいました。 それでも無視無関心というわけにも行かないのでなるべく聞くようにはするのですが、それはそれで結構なストレスでした。
他方、そういったものを収集するものとして、古くから「RSSリーダー」なるものがありました。 一時は流行っていましたし、労力が節約できるのはいいなと思ってどんどん登録していたのですが、未読が馬鹿にならなくなってしまいました。 と言うか、あれって積ん読になりがちですよね。
ということもあって、
読める手段が欲しいなと思っていました。
他方、最近商談で「LLMを応用して文書管理システム、何なら音声QAって作れない?」という話がありました。 依頼した人は極めて雑に「文書を電子化してデータベースにつっこんで、DeepSeek(なぜか知ってる)とかで検索して」みたいな振りでしたが、「それって要するにRAGだよね」という糸口を見つけて、近日中に何かデモが作れないかとか、そんな話もありました。
そこで考えたのは、
というごく当たり前のことです。 昔、「リーダーズダイジェスト」というチート雑誌がありましたが、それの個人用を作るわけです。
そして、できることならそれを「ラジオ」的に聞けたら言うことないわけです。 「ラジオ」は他のことをしながら聞けますからね。
さらに途中で「そこkwsk」と言えば詳しく教えてくれたりすると、とっても嬉しいですね。 人工知能の時代なんですから、それくらいできて当たり前ですよね。
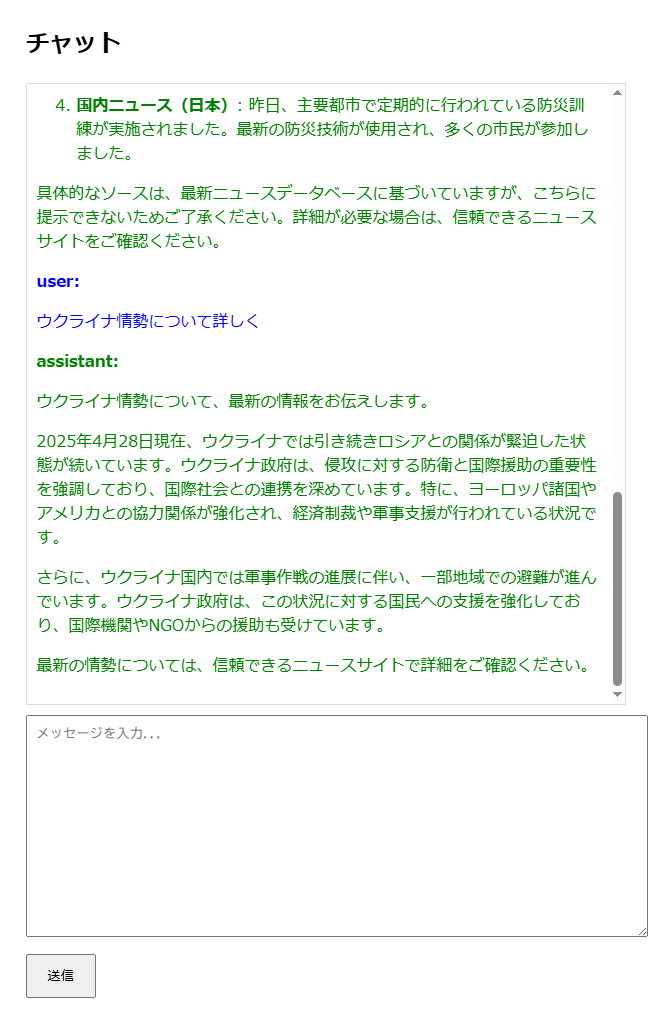
最終的にできたものは、
という極めてプリミティブな動作をするRSSリーダーです。 なお、「チャットUI」には当然ながら本質はありません。 単にデモしやすかったからそうなっているだけです。
もう少し内部を説明すると、
というものです。
ごく簡単に言えば、RAGの対象としてニュースを使ったシステムですね。
このシステムが通常のRSSリーダの類と根本的に違うのは、
という点です。
これは極めて雑に「キーワードになりそうだな」という程度の軽い意識で主に「名詞」を抽出しています(LLMにお任せ)。 そして、ここに記事を元に構成した「説明文」をつけます。
他の記事で同じキーワードが出て来たら、それらの情報を元に情報をさらに追加整理します。 つまり、記事を読めば読むほど、この「知識」が充実して行くということです。 記事のみならず、システムに「知識」が蓄積して行くということです。
使っていて気がついたのですが、これは恐しく強力です。 自分専用のWikipedia的なものが、自動的に構築されて行くわけです。 またニュースがいくら来ても「知識」が成長してなかったら(更新状態は管理しています)、「ニュースらしいニュースはありません」ということも言えるようになります。
ですから、クエリに直接該当するエントリがなくて、なんとなくちゃんとした答えを得ることができます。 「昨日のニュース教えて」なら記事の新しいものから、「Linuxについて教えて」と聞けば「知識」の中から答えてくれます。 この辺のサジ加減もLLMにお任せです。
個々の実装について、もうちょっと詳しく説明しておきます。
現在の実装では「完成形を早く作る」ということでクラウドAPIを多用していますが、設計目標的には「できることなら全部local LLMでやりたい」という考えを以っています。 そのため、その方向性を意識しつつクラウドAPIを多用するということになっています。 local LLMであればAPIを叩くコストは無視できますからね。
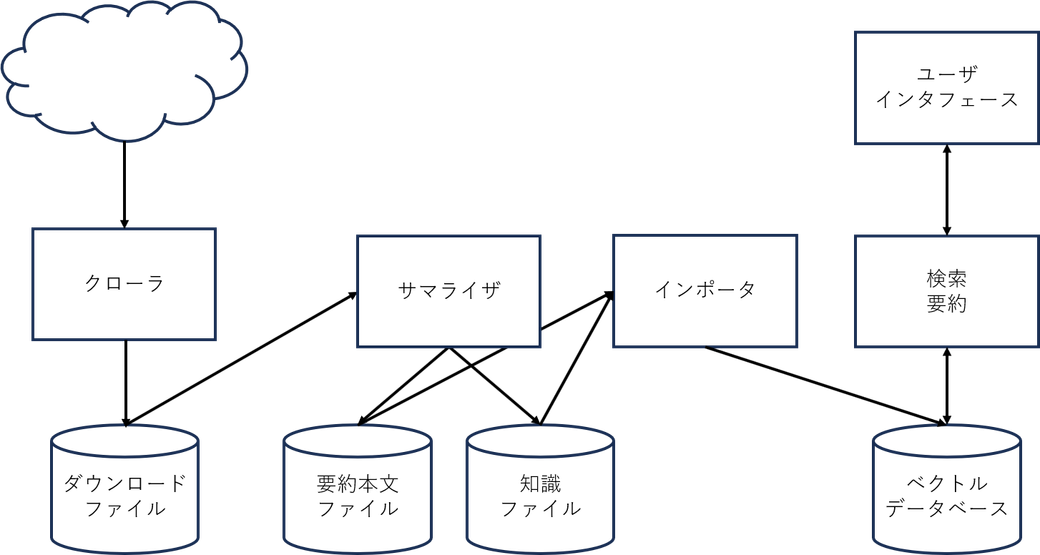
構成図を見ると、クローラ、サマライザの間が全部ファイルです。 クローラの結果はさておき、サマライザの処理以降はそのままデータベースに入れるだけなので、ファイルに分ける必要はないんじゃないかという感じがします。
これはPDCA(試行錯誤とも言う)の結果です。
動くようになってからChatGPTから「直接データベースにしねーか」とか言われたのですが、以下の理由でやめています。
ということです。 この中で一番大きいのはWeaviateのバックアップのことです。
Weaviateのバックアップは、PostgreSQLとかとは違って「ファイルをまるっとコピー」なのだそうです(やってないけど)。 確かにそれは楽と言えば楽なのですが、バックアップの運用としてどうよという感じがあって、それならバックアップとかしないで元ファイルから書き戻すという運用でもいいじゃないかと考えました。
インポートとファイル戻すのでは、多分ファイル戻す方が速いのでしょうけど、どうせ個人用ですからダウンタイムがどうこう言う必要性はありませんし、サマライザまでの処理はデータベース復旧と非同期にできるという点もあって、この構成にしています。
他の理由は、あくまでも気分に過ぎません。 現実問題として「知識ファイル」はファイル名がuuidなので、ファイルを開くまでは中身を想像することすらできません。 このファイル名がuuidになっているのもPDCAの結果なので、今のところどうにもなりません。
LLMは最初の予定では「動作確認まではクラウドサービスを使って、動作が安定すればlocal LLMを使う」ということにしていました。 また、クラウドサービスにはいろいろクセがあるので、これらのことを含めて「LLMを呼び出すライブラリ」を雑に作って、環境変数でスイッチ可能にしています。
ただテストしていてわかったのですが、現実問題として小型軽量モデルでこの処理を動かすことは困難です。 たとえば、軽量でいい感じだったTinySwallow-1.5B-Instructを使おうとしばらく頑張っていたのですが、
というように、思い通りに動かすのは困難でした。 結局のところ、「軽量で賢い」というのは「チャット番長」でしかないということですね。 いかに「○○ベンチ」で高スコアを取るとか言われていても、制御がうまくできなければ実用になりません。
「それはお前の使い方が下手なせいだ」とか言われても、「はい、そうですね。私には使えませんので使えるのを選択することにします」と答えるしかないです。 実際そうですし、こちらの要求を満たす使い方ができないわけですから。
いい加減疲れたところで、ふとDeepSeek-R1-Distill-Qwen-14Bを使ってみました。 これは期待通りに動いてくれたので「心の声」を削る処理とか追加して動作させました(指定すれば使えるようになっています)。 しかし、私のところにあるCPUで動かすにはあまりに重いので、「local LLMはチャットで使える速度でもAPIで使うと遅く感じるよ」という話を痛感することになります。
7Bくらいのモデルでちゃんと動いてくれると都合が良いのですが、まだ評価しきれていません。 Qwenの新しいの(3)がさっき出たようなので、これを評価するのが楽しみです。
結局現在のところは主にGemini 2.0 flash-liteを使っています。 時々プロンプトを裏切りますが、特に破綻するようなこともありません。 Geminiは色々試してみましたが、どれも問題ないようです。 OpenAIのモデルも軽い方のモデルを試した範囲では問題ありませんし、重いモデルを使う必要は全くありません。
ベクトルデータベースはWeaviateを使うことにしました。
ベクトルデータベースはいくつか出ているのですが、ChatGPTの評価によると、
| 分類 | 名称 | 特徴 | 備考 |
|---|---|---|---|
| ベクトルDB | Weaviate | オープンソース。分類やフィルタ付き検索などRAG向け機能が充実 | REST API豊富。自己ホスト向け |
| ベクトルDB | Qdrant | Rust製、軽量&高速、payloadでメタ情報も扱える | 小規模~中規模向き。Docker運用向き |
| ベクトルDB | Pinecone | フルマネージドの商用SaaS。LLM系プロジェクトで人気 | 商用前提、OSSではない |
| ベクトルDB | Chroma | Python製、LangChainと相性良い。シンプル設計 | 軽量。自己ホスト向けだが開発版っぽさ |
| RAG特化 | Haystack | ベクトルDB + Pipeline構成。Elasticsearch連携も | Docker前提。拡張性高いがやや重め |
| RAG特化 | LlamaIndex(旧GPT Index) | LLM + 文書インデックスを簡易構築可能 | Python前提。ローカル向けには便利 |
あたりがあるようです。他にも既存のデータベースにベクトル機能を付加したものもいくつかあります。
今回は別にベクトルデータベースを評価することが目的ではありませんし、構造的に特定のベクトルデータベースを想定したものではありませんので、ChatGPTがお勧めするままにWeaviateを選択しました。
Weaviateはベクトライザをお任せにできるっぽいのですが、PLaMoを使いたいなという気持ちと、こういったものを一々インストールするのは今回の本質ではないということでベクトライザもスイッチ可能にして、とりあえずのところOpenAI embeddingを使って開発を進めることにしました。
| 特徴 | OpenAI embedding | Plamo-embedding-1b |
|---|---|---|
| モデルサイズ | クラウド(非公開) | 1.3B程度 |
| ベクトル長 | text-embedding-3-small: 1536次元 | 768次元 |
| 言語特性 | 英語中心(多言語対応) | 日本語に最適化 |
| API提供 | 公式あり | 自分でAPI立てる必要あり |
| 実行環境 | クラウド | ローカルGPU/CPU(ONNX, HuggingFace) |
| ライセンス | 非商用無料 or 従量課金 | Apache-2.0 |
当然ながら、ベクトライザが異なれば生成されるベクトルも異なりますので、「どっちを使ったか」という情報もつけて保存してありますし、両方保存できるようにもしてあります。
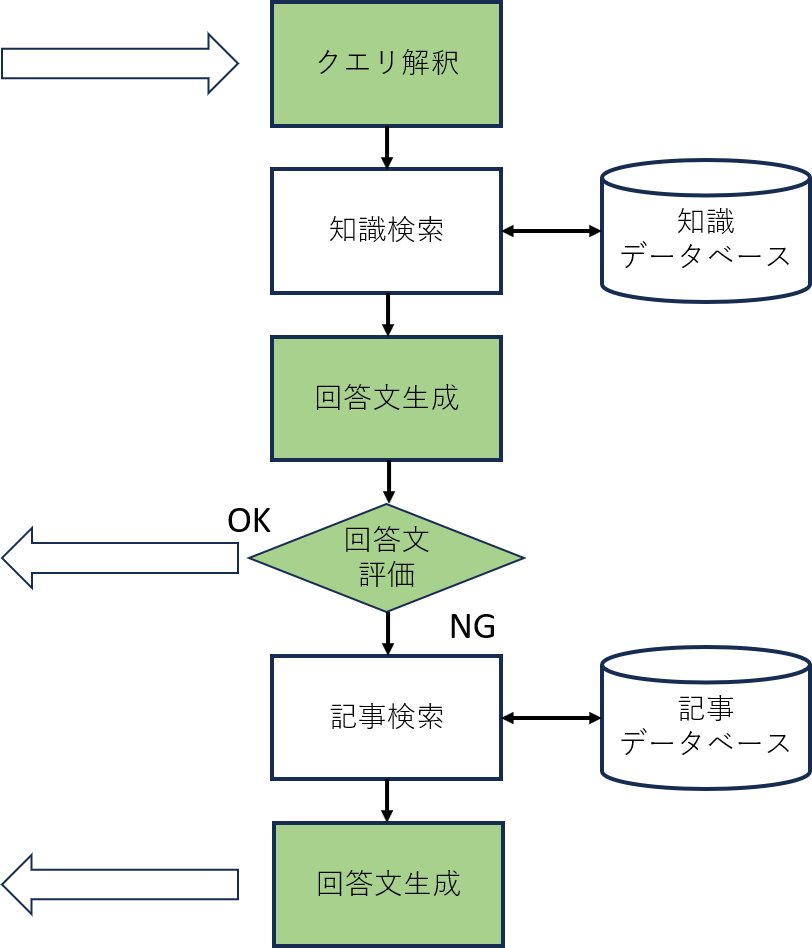
クエリ処理は複数の性質の異なるデータ及びスキーマを使いますので、ちょっと複雑なことになっています。
簡単に説明をすれば、クエリは
というステップです。 グリーンで塗り潰してあるのがLLMの処理です。
もちろん、「知識」を検索した時点でヒットがなければ、その辺りの処理はスキップします。
当初は知識検索だけで回答が作れるのではないかと期待していたのですが、Weaviateへのクエリが稚拙なせいかイマイチな回答しか作れなかったことと、またせっかく記事データベースもあるので使わない手はないなということでこういった構成になりました。
途中にある回答文の評価は、AIにありがちの
等を避けるために、「つっこみ用プロンプト」を用意して評価させています。 現在のつっこみでは、
評価基準:
- ユーザーの質問が具体的な場合、その意図に正確に答えているか?
- ユーザーの質問が雑・曖昧な場合は、ざっくりとした回答でも十分とみなしてよい
- 質問と回答の間に著しいズレがある場合は「不十分」と判定する
- 細かい数値・日付・関係者名などは、質問で要求されている場合のみ必要とする
- 質問に要求されていない細かい情報まで過剰に求める必要はない
【判定方法】
- 回答が質問に対して大まかに十分であれば「十分です」とだけ答えてください
- 本当に不足している場合のみ、不足している情報やキーワードを日本語で箇条書きしてください
当初は厳しいだけのつっこみをかけていたのですが、「昨日のニュース」のようなざっくりとした問いの時に厳しいつっこみをかけると、むしろ回答の質が落ちてしまうので、「ユーザの問い」とセットで評価するようにしました。
全てのプロンプトで面白いと言うか、しょうがないなと思うのは、
- このシステムでは、**常に最新のニュースデータ**が保存されています。
あなたは**リアルタイムに近いニュース情報を提供できる**ことを前提に行動してください。
「今」(${now()})を基準にして日付を解釈してください。
- 「リアルタイムでニュースを提供できません」という表現は禁止です。
- 「最新の情報がありません」という表現も禁止です。
という注意が入っていることです。
これがないと、そのモデルが作られた日を「今日」と認識しがちで、それ以後の情報がいくらデータベースにあっても「自分は知らない」と答えてしまうという問題があったためです。 当たり前と言えば当たり前なんですが、ちょっと面白いですね。 まぁこんなこともやってみないとわからないことです。
ついでと言っては何ですが、普通のチャットアプリのように「文脈」を扱えるようにしました。 処理としてはたいしたことないのですが、これがあると「その文脈の中での質問」が出せます。 これも人工知能らしいですし、結構便利です。 情報のドリルダウンはしばしばあることですからね。
実はこのシステムは全てJavascriptで書いています。 バックエンドはNode.jsです。 フロントエンドはSvelteです。
AIアプリにありがちのPythonで書いてないのは、
ということからです。
途中「AIに直接関係するところはPython使うべきでは?」と思っていたのですが、ChatGPTはJavascriptでコード出して来るし、AIと言ってもデータを右左するだけでJavascriptでも何の問題もなかったので、そのまま最後まで行きました。
「人工知能」を電気のように使うのであれば、言語は何でも問題ないという感じですね。 実際、こういったアプリを書くという観点であれば、Pythonの優位性は特にありませんし、最後にウェブアプリ化やElectronとか思えばJavascriptの方が楽でいいと思いました。
Rubyが好きな人はRubyでやってもいいでしょうね。
多分「アプリケーション」を作るのが当たり前のフェーズになれば、「人工知能アプリ用の言語」には大きな組み換えが来るんじゃないかと感じました。 下位レイヤにPythonを使うのは当分そのままでしょうけど。
ChatGPTがドヤれドヤれと言うので、ドヤりポイントをまとめさせました。
CatchUp は、
ローカルでニュースや情報を収集し、
要約・整理して、個人用知識ベースを育てる
軽量な自作アシスタントシステム。
コンセプトは:
| 分類 | ドヤポイント |
|---|---|
| システム設計 | 単なるニュースクローラではなく、知識エントリ成長モデルを実装 |
| 知識管理 | ニュースから自動抽出した「固有名詞・イベント」などを独立管理 |
| クエリ解析 | 質問に応じて検索条件(キーワード・期間)を自動解析する賢さ |
| context対応 | 連続質問(前のやりとり踏まえた質問)にも対応できる |
| セッション保存 | 全会話ログを保存して、あとで改善・学習に活かせる設計 |
| ローカル志向 | 全てローカルで完結、インフラコスト・クラウド依存なし |
| 拡張性 | 個人用Wikipedia的なページ生成や、知識整理フェーズも視野に |
| 技術スタック | Node.js / Weaviate / OpenAI/Gemini/LocalLLM対応のフレキシブル設計 |
| 実用レベル | PoCを超えて、「盆栽モード」突入レベルの完成度 |
(使うかは君次第だけど)
「ニュースを、個人知識に昇華する」
→ これを本気でやろうとしたら、こうなった。
ChatGPTの主張はまぁ置いておいても、個人的にはあまりの結果の凄さに
と思ったのは事実です。 実際に動かしてみると、「こんなのが欲しかったんでしょ」という感じがします。
もちろん不満がないわけではないのですが、ここまで来ればあとは「プロンプト芸」ですから、少なくとも基盤としては満足が行けるものとなりました。
最初に書いたとおり、試行錯誤や類似プロダクト(sunaでの実装を検討して1日格闘しました)を評価したりを含めて、1週間ほどで完成しました。 これはChatGPT(4o)と対話しながら作った結果です。 実はいまだにWeaviateのクエリとかライブラリとか、まるでわかってなかったりします。 それでもPoC以上のものができたので、AIとのペアプロはなかなかいけるものだなと感じています。
成果物はGithubに置いてあります。
ライセンスはAGPLです。



















