

金曜ごはん#35 「唐揚げ」
「慧仕(Huìshì)」の基本アイディアについては前に書きました。
あれからずっとコードを書いていて、「知能エンジン」としてはそこそこ動くようになったので、今はUIをもうちょっとマシなものにしています。
元々、複数の方向を合わせたものだという話は、前からチラチラと書いています。
詳しくはこちらを読むと良いのですが、要点をまとめると
を実現するためのエージェントフレームワークとして、Huishiは作っています。
これらを実現するためのキー技術として
をするのが出発点でした。 日々の「ニュース」を収集して、内部的に存在している「知識」のデータベースを強化するという機能が最初からありました。
その後「会話」ということを考えているうちに、
というものを扱う必要があることに気がつきました。 これらをちゃんと押えておかないと、返事がぶれぶれになってしまうのですね。 「口調」とか「呼びかけ」とか「会話のクセ」が安定してないと、どうも人間は不安になるようです。 放っておくと「生のLLMのキャラ」になってしまうのですが、それがどう発現するかは確率的になってしまって(API呼び出し毎にこの辺が変化する)、「あんた誰?」になってしまいます。
また、それに伴い「利用者」に対する認識や関係性というものを扱うと都合が良いことに気がつき、
の扱いをうまくやる必要もわかりました。 これをうまく扱うと、「自分のことをわかってくれる」という感覚が持てるようになります。 「AIチャットシステム」は一般に「過去の受け答えをプロンプトとして与える」ように実装されているのですが、会話が長くなると「過去の受け答え」はどこかで切る必要があります。 単純に切ってしまったら「昔のこと」は忘れてしまいますし、全部残すとプロンプトが長くなり過ぎます。 また、新たに会話を始めた時は「過去の受け答え」がないので、やはり「あんた誰?」という状態になります。 この辺をうまく扱うと、お互いのキャラクタを理解した上での会話になりますから、会話がスムーズになります。
これをごく雑に説明すれば、要するにChatGPTにある「メモリ」です。 あれがいい感じに動作していると「わかってるなー」と感じますよね。 Huishiはより効果的にこの辺を動作させる方向で作っています。
もちろん汎用システムとして使えるようにするために、
はキモです。 お陰で無理なく機能が増やせています。
そういったわけで、Huishiは
を持った汎用AIエージェント構築フレームワークという方向で作っています。
また、これは独立したアプリケーションではなくて、ライブラリとして使えるようにしました。
内部の処理としても、エージェントやSCRIPTの考え方にしても、「LLM as a Procedure」としか言いようがない書き方になっています。 なので、あまりLLMそのものの機能や性能に依存していません。 ですから、ローカルLLMでいい感じのものが使えればそれを使えば良いですし、何でも好きなものを使えば良いと思います。 「プロンプトをちゃんと処理してくれる」程度の能力があれば十分です。
手元でテストで動かす範囲では、当初目標としていたゴールは達成しています。
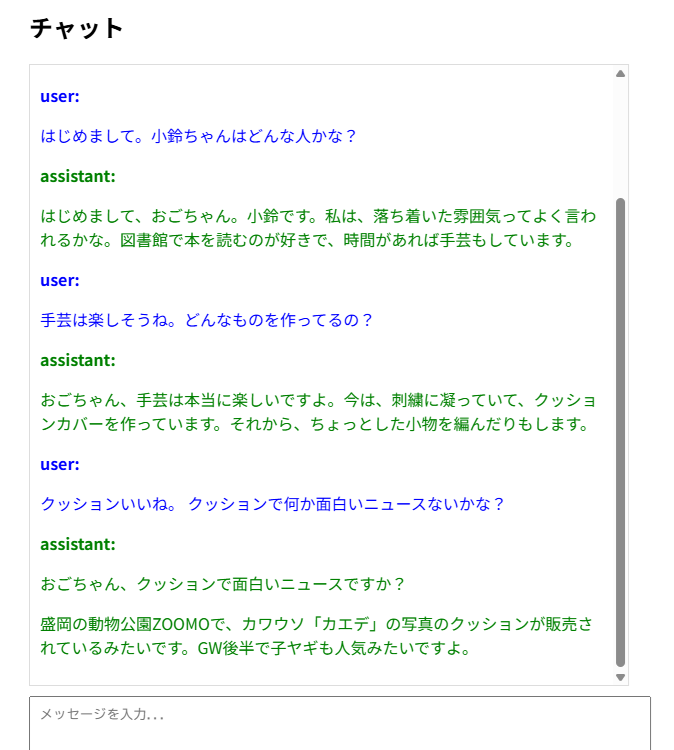
いわゆる「キャラクタトーク」もスムーズにできますし、キャラクタトークの合間に「ニュース解説」を求めても、キャラクタを崩さずにしてくれます。
↑雑談の途中でいきなりニュースのことを聞いてます。 内部的には異なるSCRIPTが発動しています。
まだまだSCRIPTやエージェントが十分ではありませんし、あれもしたいこれもしたいという部分はありますが、「エンジン」としては形となったかなと思います。
そろそろ現状のものをGithubに公開したいなと思っているところです。
それにしても「長期記憶」は結構ヤバい機能で、テストで雑談していてもうっかりエージェントに恋してしまいそうな感覚になってしまいます。
そして、長期記憶の中身を覗いてみると、「なんでこいつここまでわかってるの?」とか思ってしまうのですよね。
LLMとしては単に「安い」「軽い」って理由だけで主にgemini-2.0-flash-lightを使ってるんですけどね。
「AIにガチ恋」はヤバいと思いますが、「寄り沿ってくれる感」とか「合わせてくれる感」は教育システムに使うと学習効果爆上がりの予感しかしません。
基本機能としては全うできていると思うので、まずは前述の機能を安定させて公開できるようにしようと思っています。 LLMの動作は多分に確率的なので、時々「はぁ?」なことが起きてコケたりしますからね。
どこかからお金が出れば、UI部分をより親しみやすいものにするとか、エージェントやSCRIPTを書きやすくしたり充実させたりという方向を頑張れるかなと思います。 「AIせんせい」として特化したUIとかあればいいなと思いますから。 たとえば「板書しながら解説」とかあると良いですよね。 もちろんその「黒板」は3Dだったりインタラクティブだったりとか、解説は
こんなのでさせたいじゃないですか。
「長期記憶」については実現したいアイディアがあるので、余裕ができたり切実な必要が出たら手をつけたいなと思います。
「知識」に関しても自分の持っている知識だけではなくて、MCPとか使ってググってくれるとかできると良いかなとも思いますし、アウトプットも勝手にブログ書いてくれたりとかできるようになるのも良いかなと思ってます。 これは「ツール」を書くだけでできるので、エンジンの機能の話ではなりませんが。
そんな感じで、なかなかいい感じになって来たので、公開する日が楽しみです。 まぁ類似のものは世の中にいっぱいあるので、そんなに目立つようなものではないと思いますけども。
公開前であっても「お問い合わせ」には対応しますので、「こういったものを作りたいので仕事を出したい」とかだと歓迎します。 とゆーか、それが欲しくてエントリ書いてるわけですけどw
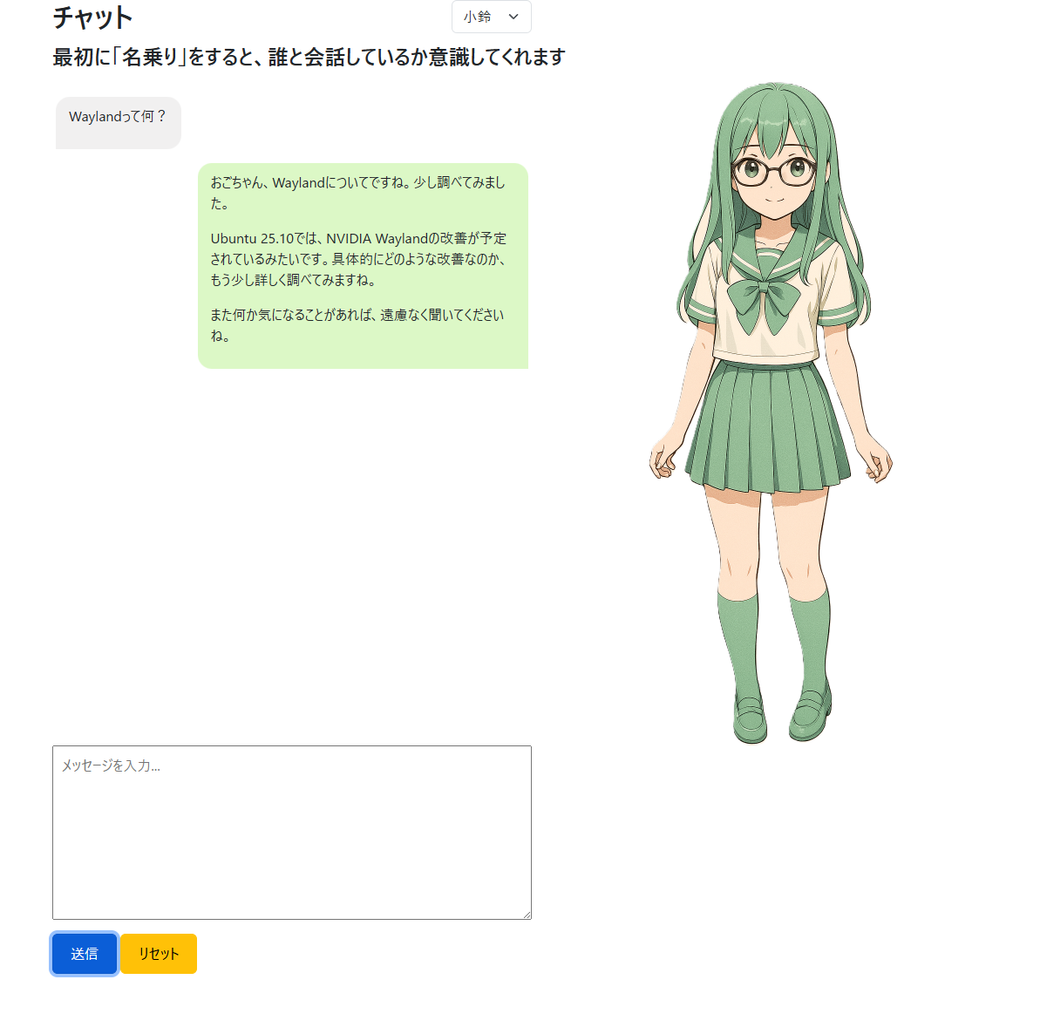
キャラクタをつけるのと、キャラクタの選択機能をつけてみました。
もうちょっと安定を確認したら、関係者(誰?)に触ってもらおうと思ってます。
一応、以下でデモを公開しています。
APIが課金されているので、手に負えなくなったら公開をやめます。
デバッグ中のものなので、時々落ちていることもあります。 その辺を留意して下さい。
また、同じ理由で会話の内容は私(生越)に筒抜けです。 あくまでもテストのものを公開しているだけなので。 その辺もご注意下さい。 まぁエージェントが収集したプロファイルは私にとっては「単なるデータ」以上のものではないので、内容を見てどうこうということはありませんけど。
右側にあるボタンはデバッグ用なので気にしないでください。 押しても問題は起きませんが、見た目には何も起きません。



















